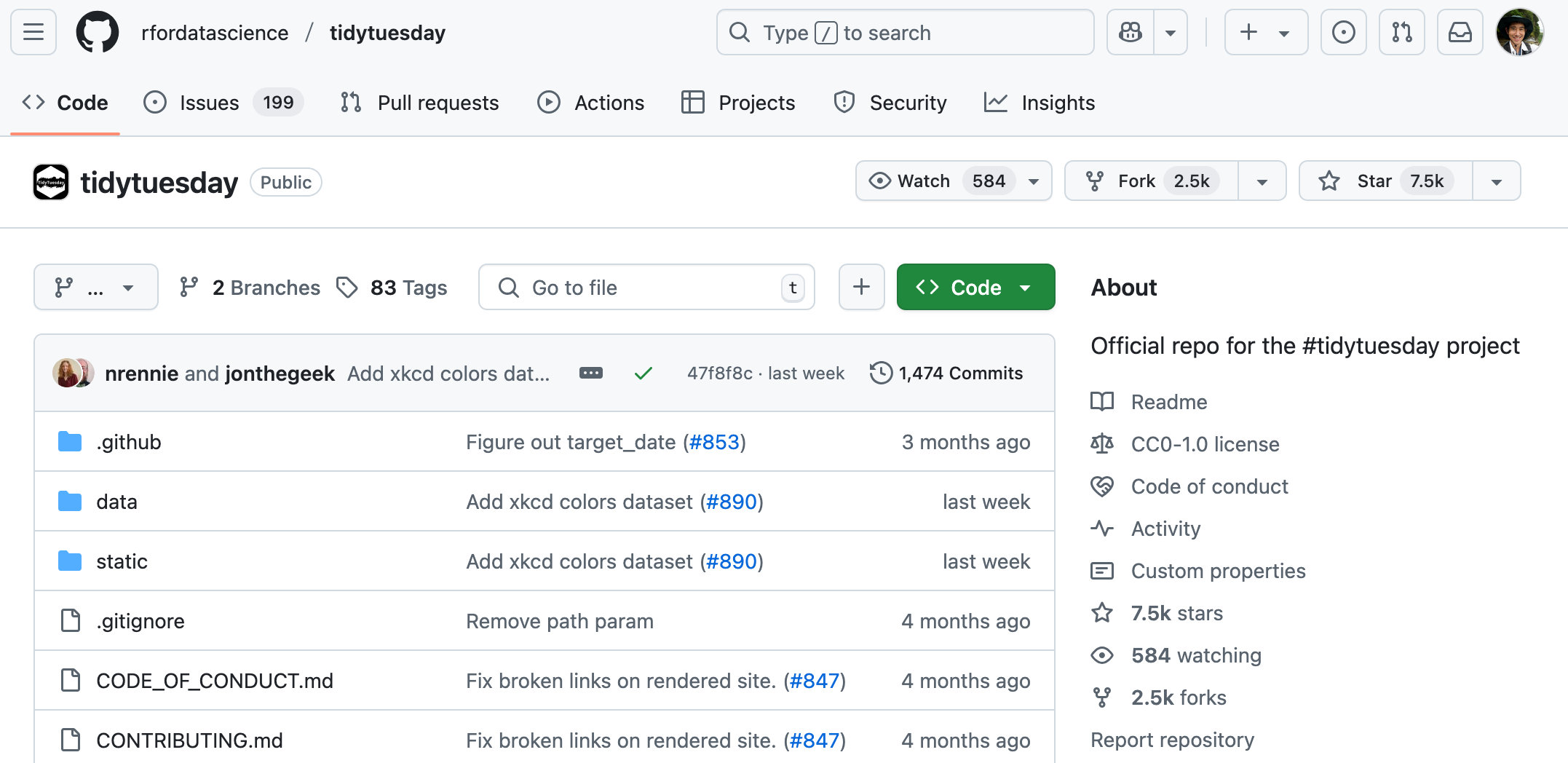
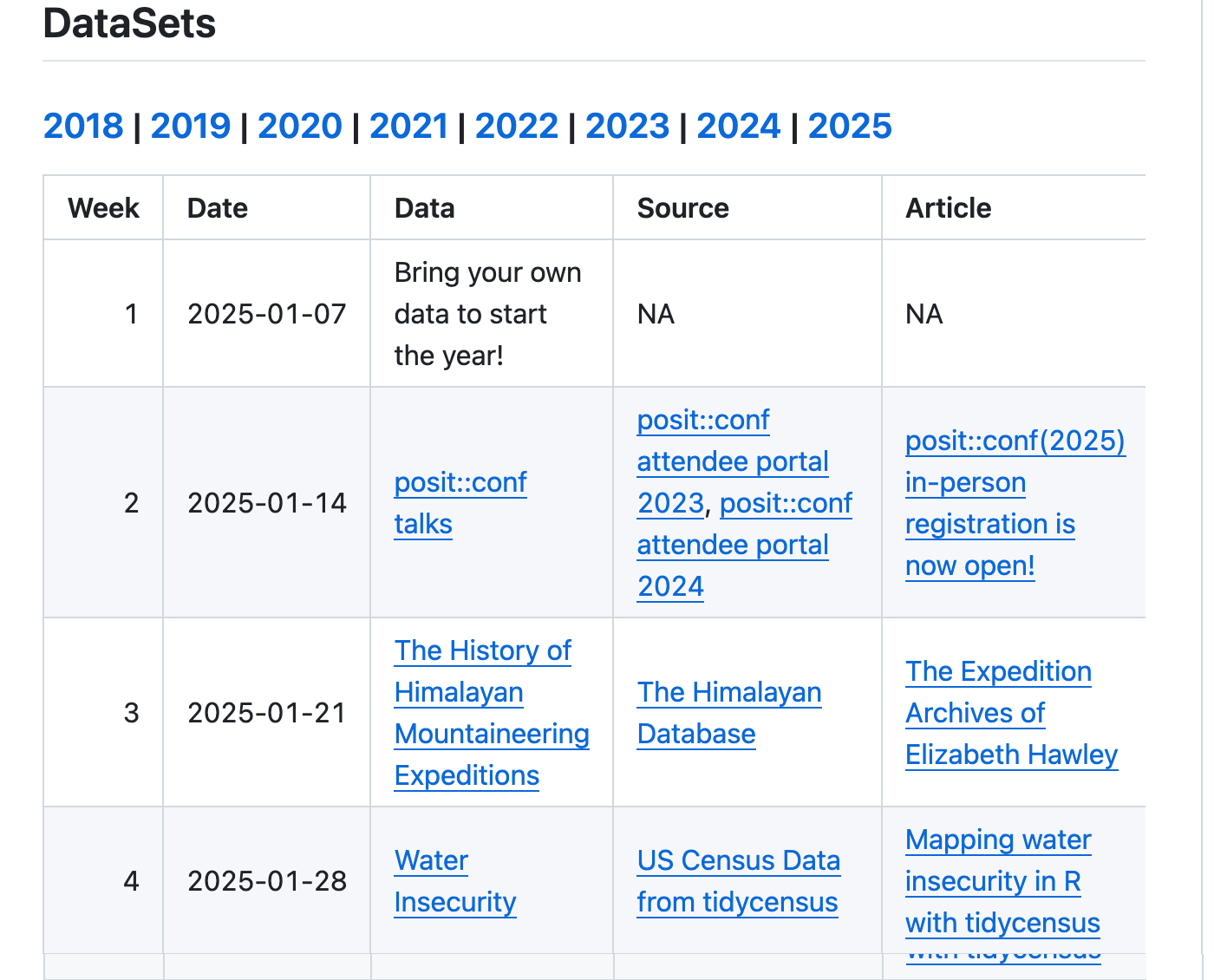
Scroll down until you reach the section labeled “DataSets”.
“DataSets” section
Once you find a dataset that sounds interesting, click on its link in the “Data” column.
For example, I think “The History of Himalayan Mountaineering Expeditions” dataset sounds interesting, so I’ll click on that.
“DataSets” section
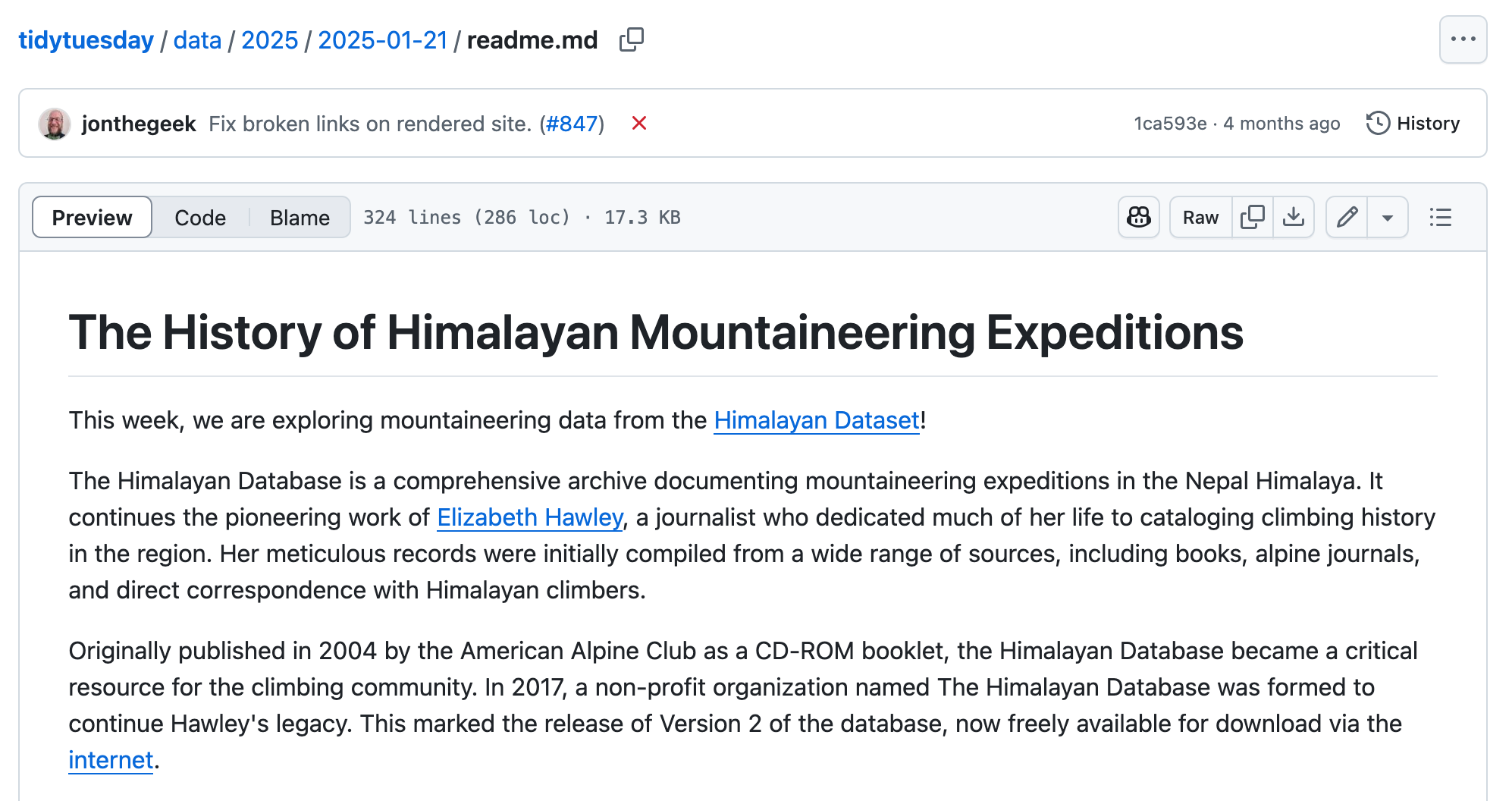
This will take us to the README file (a file that explains basic info about a piece of software, dataset, or analysis) for the “History of Himalayan Mountaineering Expeditions” dataset.
---- Compiling #TidyTuesday Information for 2025-01-21 ----
--- There are 2 files available ---
── Downloading files ───────────────────────────────────────────────────────────
1 of 2: "exped_tidy.csv"
2 of 2: "peaks_tidy.csv"
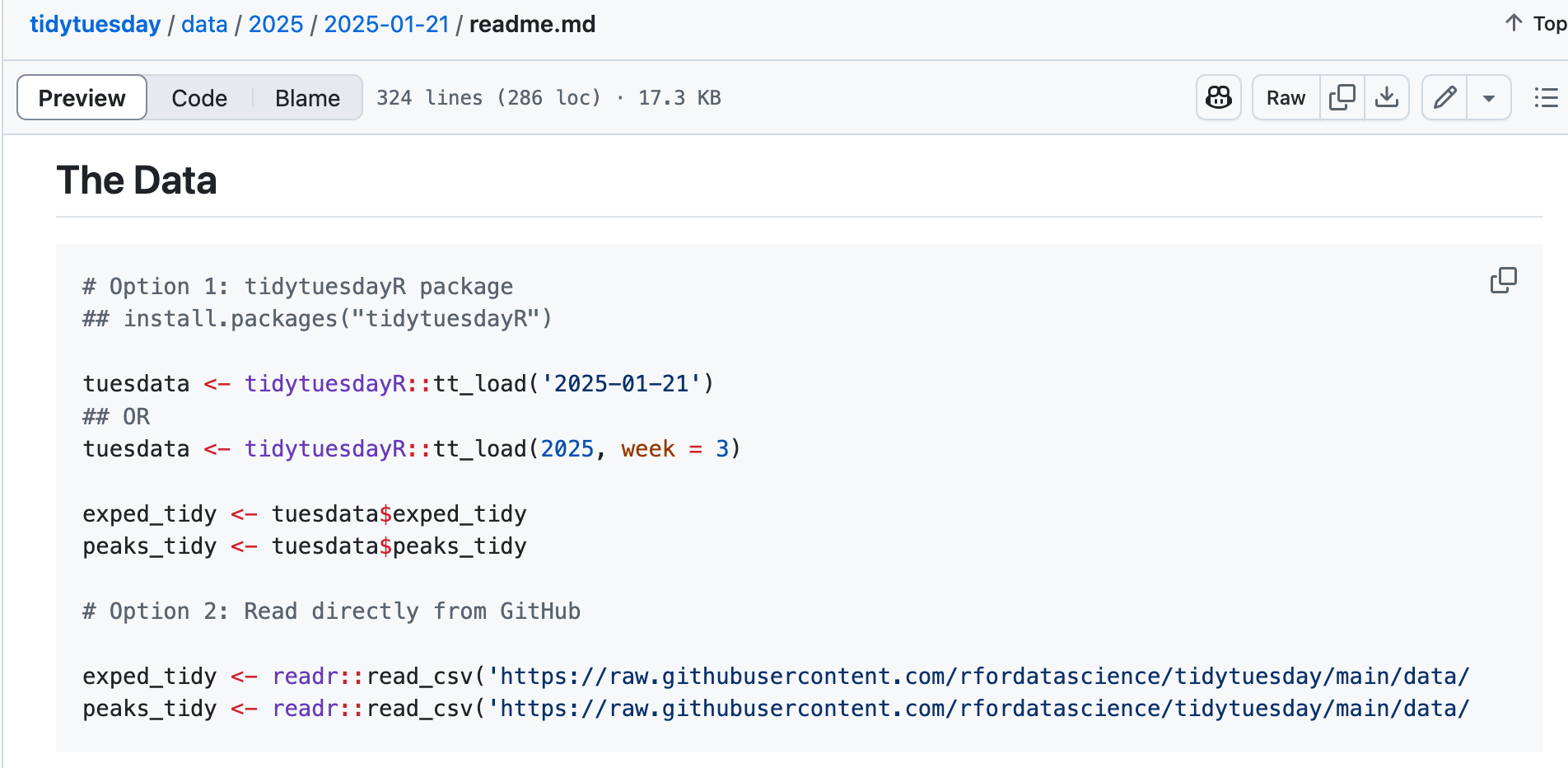
Note that the TidyTuesday webpage shows tidytuesdayR::tt_load("2025-01-21"), but this does the same thing as running library(tidytuesdayR) followed by tt_load("2025-01-21").
Also, when you use Option 1, the data are loaded as a list, so we need to extract each dataframe from the list. For the himalaya data, there are two dataframes. It shows us how to extract them from the list using the $ symbol:
Note that since there are two dataframes in this dataset, you may need to join them in order to conduct the data analysis.
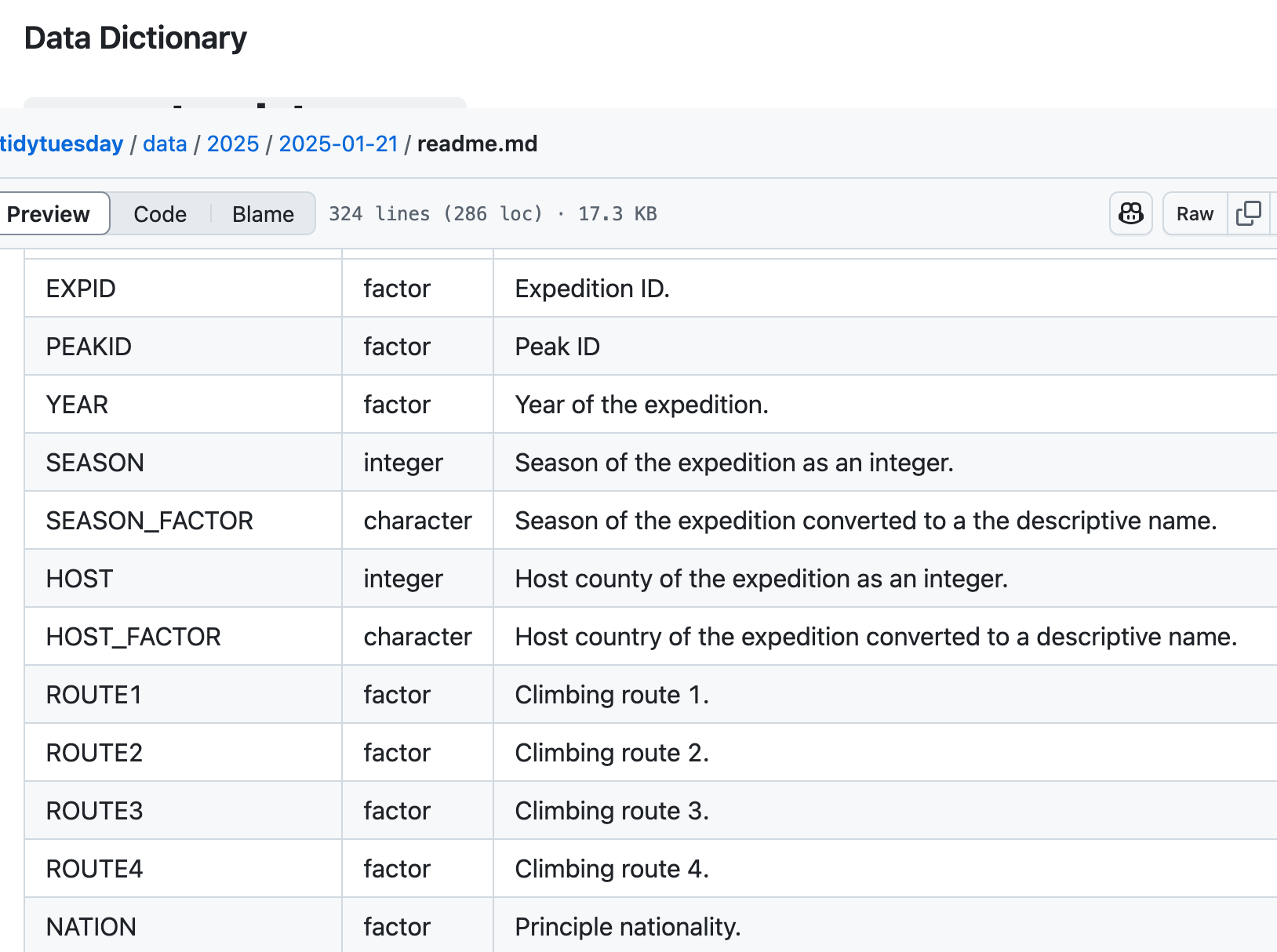
Check the Data Dictionary
Every dataset in TidyTuesday includes a “Data Dictionary” that explains what each column in the data means. Scroll down the README file a bit further to find it. This is very important for understanding and analyzing your data.
Data Dictionary for the Himalayan Mountaineering Expeditions dataset
Start exploring the data!
For example, let’s count the names of the mountain peaks included in the peaks_tidy data:
peaks_tidy |>count(PKNAME)
# A tibble: 480 × 2
PKNAME n
<chr> <int>
1 Aichyn 1
2 Ama Dablam 1
3 Amotsang 1
4 Amphu Gyabjen 1
5 Amphu I 1
6 Amphu Middle 1
7 Anidesh Chuli 1
8 Annapurna I 1
9 Annapurna I East 1
10 Annapurna I Middle 1
# ℹ 470 more rows
Once you get a feel for the columns in the dataset, try making some plots.
Your goal is to create a plot that tells the story hidden in the data. Good luck!